Hello again, where were we? … Oh yes, we have been discussing CoreML and have even set up an appropriate python 2 environment to work with CoreML. In this post we are going to cover some of the most basic aspects of the workhorse of machine learning: the dependable linear regression model.
We are indeed all familiar with a line of best fit, and I am sure that many of us remember doing some by hand (you know who you are) and who hasn’t played with Excel’s capabilities? In a nutshell, a linear regression is a model that relates a variable 
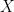

Let us take the case of 2 independent variables 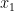


where 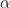

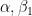

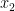
In the next post we will show how we can do this for the Boston House Prices dataset using a couple of variables such as number of bedrooms in the property and a crime index for the area. Remember that the aim will be to show how to build the model to be used with CoreML and not a perfect model for the prediction.
Keep in touch.
-j
Pingback: CoreML - Boston Prices exploration - Quantum Tunnel Website
Pingback: CoreML - Building the model for Boston Prices - Quantum Tunnel Website
Pingback: CoreML - Model properties - Quantum Tunnel Website
Comments are closed.